Understating why we need to initialize posteriors or messages in RxInfer
In certain models, after completing the model specification step and moving on to execute the inference procedure, you may encounter an error prompting you to initialize required marginals and messages. Understanding why this step is necessary can be perplexing. This tutorial is designed to explore the intuition behind model initialization using a practical example
RxInfer.@initialization — Macro@initializationMacro for specifying the initialization state of a model. Accepts either a function or a block of code. Allows the specification of initial messages and marginals that can be applied to a model in the infer function.
The syntax for the @initialization macro is similar to the @constraints and @meta macro. An example is shown below:
using RxInfer
@model function submodel(z, x)
t := x + 1
z ~ Normal(mean = t, var = 1.0)
end
@model function mymodel(y)
x ~ Normal(mean = 0.0, var = 1.0)
z ~ submodel(x = x)
y ~ Normal(mean = z, var = 1.0)
end
@initialization begin
# Initialize the marginal for the variable x
q(x) = vague(NormalMeanVariance)
# Initialize the message for the variable z
μ(z) = vague(NormalMeanVariance)
# Specify the initialization for a submodel of type `submodel`
for init in submodel
q(t) = vague(NormalMeanVariance)
end
# Specify the initialization for a submodel of type `submodel` with a specific index
for init in (submodel, 1)
q(t) = vague(NormalMeanVariance)
end
endInitial state:
q(x) = NormalMeanVariance{Float64}(μ=0.0, v=1.0e12)
μ(z) = NormalMeanVariance{Float64}(μ=0.0, v=1.0e12)
Init for submodel submodel =
q(t) = NormalMeanVariance{Float64}(μ=0.0, v=1.0e12)
Init for submodel (submodel, 1) =
q(t) = NormalMeanVariance{Float64}(μ=0.0, v=1.0e12)
Similar to the @constraints macro, the @initialization macro also supports function definitions:
@initialization function my_init()
# Initialize the marginal for the variable x
q(x) = vague(NormalMeanVariance)
# Initialize the message for the variable z
μ(z) = vague(NormalMeanVariance)
# Specify the initialization for a submodel of type `submodel`
for init in submodel
q(t) = vague(NormalMeanVariance)
end
# Specify the initialization for a submodel of type `submodel` with a specific index
for init in (submodel, 1)
q(t) = vague(NormalMeanVariance)
end
endmy_init (generic function with 1 method)The result of the initialization macro can be passed to the infer function with a keyword argument called initialization.
Part 1. Framing the problem
John has recently acquired a new car and is keenly interested in its fuel consumption rate. He holds the belief that this rate follows a linear relationship with the variable speed. To validate this hypothesis, he plans to conduct tests by driving his car on the urban roads close to his home, recording both the fuel consumption and speed data. To ascertain the fuel consumption rate, John has opted for Bayesian linear regression as his analytical method.
using Random, Plots, StableRNGs
function generate_data(a, b, v, nr_samples; rng = StableRNG(1234))
x = float.(collect(1:nr_samples))
y = a .* x .+ b .+ randn(rng, nr_samples) .* sqrt(v)
return x, y
end;
# For demonstration purposes we generate some fake data
x_data, y_data = generate_data(0.5, 25.0, 1.0, 250)
scatter(x_data, y_data, title = "Dataset (City road)", legend=false)
xlabel!("Speed")
ylabel!("Fuel consumption")
Univariate regression with known noise
First, he drives the car on a urban road. John enjoys driving on the well-built, wide, and flat urban roads. Urban roads also offer the advantage of precise fuel consumption measurement with minimal noise. Therefore John models the fuel consumption $y_n\in\mathbb{R}$ as a normal distribution and treats $x_n$ as a fixed hyperparameter:
\[\begin{aligned} p(y_n \mid a, b) = \mathcal{N}(y_n \mid a x_n + b , 1) \end{aligned}\]
The recorded speed is denoted as $x_n \in \mathbb{R}$ and the recorded fuel consumption as $y_n \in \mathbb{R}$. Prior beliefs on $a$ and $b$ are informed by the vehicle manual.
\[\begin{aligned} p(a) &= \mathcal{N}(a \mid m_a, v_a) \\ p(b) &= \mathcal{N}(b \mid m_b, v_b) \end{aligned}\]
Together they form the probabilistic model $p(y, a, b) = p(a)p(b) \prod_{N=1}^N p(y_n \mid a, b),$ where the goal is to infer the posterior distributions $p(a \mid y)$ and $p(b\mid y)$.
In order to estimate the two parameters with the recorded data, he uses a RxInfer.jl to create the above described model.
using RxInfer
@model function linear_regression(y, x)
a ~ Normal(mean = 0.0, variance = 1.0)
b ~ Normal(mean = 0.0, variance = 100.0)
y .~ Normal(mean = a .* x .+ b, variance = 1.0)
endDelighted with the convenience offered by the package's inference function (infer), he appreciates the time saved from building everything from the ground up. This feature allows him to effortlessly obtain the desired results for his specific road. Upon consulting the documentation, he proceeds to run the inference function.
results = infer(
model = linear_regression(),
data = (y = y_data, x = x_data),
returnvars = (a = KeepLast(), b = KeepLast()),
iterations = 20,
free_energy = true
)Oeps! Exception?
exception =
│ Variables [ a, b ] have not been updated after an update event.
│ Therefore, make sure to initialize all required marginals and messages. See `initialization` keyword argument for the inference function.
│ See the function documentation for detailed information regarding the initialization.After running the inference procedure an error appears, which prompts him to initialize all required messages and marginals. Now, John is left pondering the reason behind this requirement. Why is it necessary? Should he indeed initialize all messages and marginals? And if so, how might this impact the inference procedure?
Part 2. Why and What to initialize
Before delving too deeply into the details, it's important to understand that RxInfer constructs a factorized representation of your model using a factor graph. In this structure, inference is executed through message passing.
A challenge arises when RxInfer generates the FFG representation with structural loops in certain parts of the graph. These loops indicate that a message or marginal within the loop depends not only on its prior but also on itself. Consequently, proper initialization is crucial for initiating the inference process. Two general rules of thumb guide this initialization, although the intricate details are beyond the scope of this tutorial:
1. Initiate as few messages/marginals as possible when dealing with a loop structure, it will be more efficient and accurate. 2. Prioritize initializing marginals over messages.
How to identify and handle the loops?
Identifying loops is currently a manual process, as the current version of RxInfer doesn't support a graphical representation of the created graph. As such, the manual process involves:
1. Deriving the graphical representation of the model, 2. Identifying loops and the messages or marginals that need to be initialized within the loop.
However, once you receive the message Variables [x, y, z] have not been updated after an update event, it is a good indication that there is a loop in your model. If you see this message, you should check your model for loops and try to initialize the messages and/or marginals that are part of the loop.
Deriving factor graph and identifying the loops
John proceeds to derive the factor graph for his problem where he identifies where the loops are:
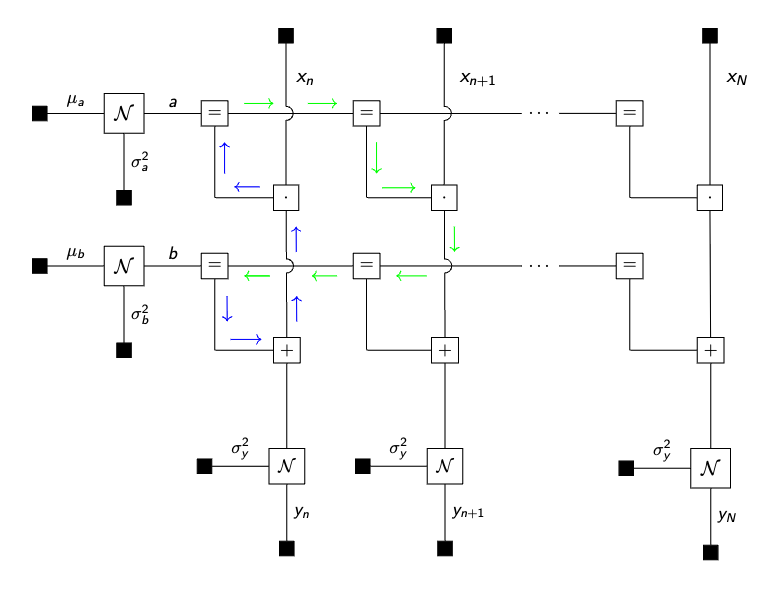
He does note that there is a loop in his model, namely all $a$ and $b$ variables are connected over all observations, therefore he needs to initialize one of the messages and run multiple iterations for the loopy belief propagation algorithm. It is worth noting that loopy belief propagation is not guaranteed to converge in general and might be highly influenced by the choice of the initial messages in the initialization argument. He is going to evaluate the convergency performance of the algorithm with the free_energy = true option:
init = @initialization begin
μ(b) = NormalMeanVariance(0.0, 100.0)
end
results = infer(
model = linear_regression(),
data = (y = y_data, x = x_data),
initialization = init,
returnvars = (a = KeepLast(), b = KeepLast()),
iterations = 20,
free_energy = true
)
# drop first iteration, which is influenced by the `initmessages`
plot(2:20, results.free_energy[2:end], title="Free energy", xlabel="Iteration", ylabel="Free energy [nats]", legend=false)
Now the inference runs without the error! 🎉
as = rand(results.posteriors[:a], 100)
bs = rand(results.posteriors[:b], 100)
p = scatter(x_data, y_data, title = "Linear regression with more noise", legend=false)
xlabel!("Speed")
ylabel!("Fuel consumption")
for (a, b) in zip(as, bs)
global p = plot!(p, x_data, a .* x_data .+ b, alpha = 0.05, color = :red)
end
plot(p, size = (900, 400))
Implementation details
RxInfer.InitializationPlugin — TypeMetaPlugin(init)A plugin that adds a init information to the factor nodes of the model.
RxInfer.convert_init_object — Functionconvert_init_object(e::Expr)Converts a variable init or a factor init call on the left hand side of a init specification to a GraphPPL.MetaObject.
Arguments
e::Expr: The expression to convert.
Returns
Expr: The resulting expression with the variable reference or factor function call converted to aGraphPPL.MetaObject.
Examples