This example has been auto-generated from the examples/ folder at GitHub repository.
Bayesian Linear Regression Tutorial
This notebook is an extensive tutorial on Bayesian linear regression with RxInfer and consists of two major parts:
- The first part uses a regular Bayesian Linear Regression on a simple application of fuel consumption for a car with synthetic data.
- The second part is an adaptation of a tutorial from NumPyro and uses Hierarchical Bayesian linear regression on the OSIC pulmonary fibrosis progression dataset from Kaggle.
# Activate local environment, see `Project.toml`
import Pkg; Pkg.activate(".."); Pkg.instantiate();using RxInfer, Random, Plots, StableRNGs, LinearAlgebra, StatsPlots, LaTeXStrings, DataFrames, CSV, GLMPart 1. Bayesian Linear Regression
John recently purchased a new car and is interested in its fuel consumption rate. He believes that this rate has a linear relationship with speed, and as such, he wants to conduct tests by driving his car on different types of roads, recording both the fuel usage and speed. In order to determine the fuel consumption rate, John employs Bayesian linear regression.
Univariate regression with known noise
First, he drives the car on a urban road. John enjoys driving on the well-built, wide, and flat urban roads. Urban roads also offer the advantage of precise fuel consumption measurement with minimal noise. Therefore John models the fuel consumption $y_n\in\mathbb{R}$ as a normal distribution and treats $x_n$ as a fixed hyperparameter:
\[\begin{aligned} p(y_n \mid a, b) = \mathcal{N}(y_n \mid a x_n + b , 1) \end{aligned}\]
The recorded speed is denoted as $x_n \in \mathbb{R}$ and the recorded fuel consumption as $y_n \in \mathbb{R}$. Prior beliefs on $a$ and $b$ are informed by the vehicle manual.
\[\begin{aligned} p(a) &= \mathcal{N}(a \mid m_a, v_a) \\ p(b) &= \mathcal{N}(b \mid m_b, v_b) \end{aligned}\]
Together they form the probabilistic model $p(y, a, b) = p(a)p(b) \prod_{N=1}^N p(y_n \mid a, b),$ where the goal is to infer the posterior distributions $p(a \mid y)$ and $p(b\mid y)$.
He records the speed and fuel consumption for the urban road which is the xdata and ydata.
function generate_data(a, b, v, nr_samples; rng=StableRNG(1234))
x = float.(collect(1:nr_samples))
y = a .* x .+ b .+ randn(rng, nr_samples) .* sqrt(v)
return x, y
end;x_data, y_data = generate_data(0.5, 25.0, 1.0, 250)
scatter(x_data, y_data, title = "Dataset (City road)", legend=false)
xlabel!("Speed")
ylabel!("Fuel consumption")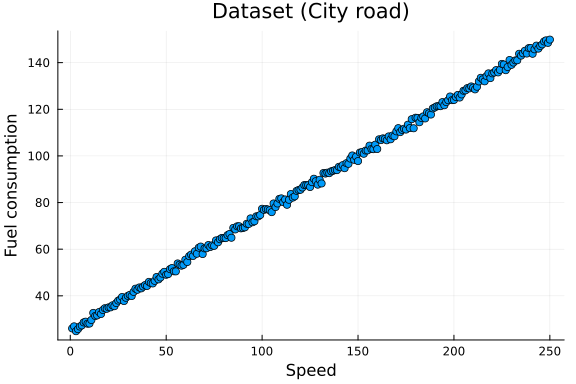
In order to estimate the two parameters with the recorded data, he uses a RxInfer.jl to create the above described model.
@model function linear_regression(x, y)
a ~ Normal(mean = 0.0, variance = 1.0)
b ~ Normal(mean = 0.0, variance = 100.0)
y .~ Normal(mean = a .* x .+ b, variance = 1.0)
endHe is delighted that he can utilize the inference function from this package, saving him the effort of starting from scratch and enabling him to obtain the desired results for this road. He does note that there is a loop in his model, namely all $a$ and $b$ variables are connected over all observations, therefore he needs to initialize one of the messages and run multiple iterations for the loopy belief propagation algorithm. It is worth noting that loopy belief propagation is not guaranteed to converge in general and might be highly influenced by the choice of the initial messages in the initialization argument. He is going to evaluate the convergency performance of the algorithm with the free_energy = true option:
results = infer(
model = linear_regression(),
data = (y = y_data, x = x_data),
initialization = @initialization(μ(b) = NormalMeanVariance(0.0, 100.0)),
returnvars = (a = KeepLast(), b = KeepLast()),
iterations = 20,
free_energy = true
)Inference results:
Posteriors | available for (a, b)
Free Energy: | Real[450.062, 8526.84, 4960.42, 2949.02, 1819.14, 1184
.44, 827.897, 627.595, 515.064, 451.839, 416.313, 396.349, 385.129, 378.821
, 375.274, 373.279, 372.156, 371.524, 371.167, 370.966]He knows the theoretical coefficients and noise for this car from the manual. He is going to compare the experimental solution with theoretical results.
pra = plot(range(-3, 3, length = 1000), (x) -> pdf(NormalMeanVariance(0.0, 1.0), x), title=L"Prior for $a$ parameter", fillalpha=0.3, fillrange = 0, label=L"$p(a)$", c=1,)
pra = vline!(pra, [ 0.5 ], label=L"True $a$", c = 3)
psa = plot(range(0.45, 0.55, length = 1000), (x) -> pdf(results.posteriors[:a], x), title=L"Posterior for $a$ parameter", fillalpha=0.3, fillrange = 0, label=L"$p(a\mid y)$", c=2,)
psa = vline!(psa, [ 0.5 ], label=L"True $a$", c = 3)
plot(pra, psa, size = (1000, 200), xlabel=L"$a$", ylabel=L"$p(a)$", ylims=[0,Inf])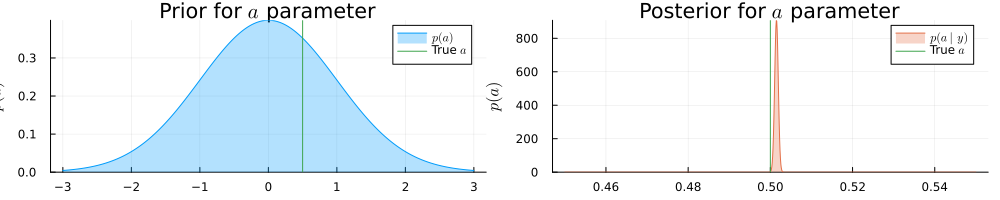
prb = plot(range(-40, 40, length = 1000), (x) -> pdf(NormalMeanVariance(0.0, 100.0), x), title=L"Prior for $b$ parameter", fillalpha=0.3, fillrange = 0, label=L"p(b)", c=1, legend = :topleft)
prb = vline!(prb, [ 25 ], label=L"True $b$", c = 3)
psb = plot(range(23, 28, length = 1000), (x) -> pdf(results.posteriors[:b], x), title=L"Posterior for $b$ parameter", fillalpha=0.3, fillrange = 0, label=L"p(b\mid y)", c=2, legend = :topleft)
psb = vline!(psb, [ 25 ], label=L"True $b$", c = 3)
plot(prb, psb, size = (1000, 200), xlabel=L"$b$", ylabel=L"$p(b)$", ylims=[0, Inf])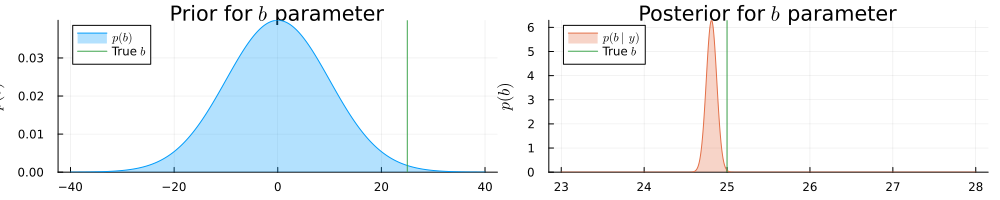
a = results.posteriors[:a]
b = results.posteriors[:b]
println("Real a: ", 0.5, " | Estimated a: ", mean_var(a), " | Error: ", abs(mean(a) - 0.5))
println("Real b: ", 25.0, " | Estimated b: ", mean_var(b), " | Error: ", abs(mean(b) - 25.0))Real a: 0.5 | Estimated a: (0.501490188462706, 1.9162284531300301e-7) | Err
or: 0.001490188462705988
Real b: 25.0 | Estimated b: (24.81264210195605, 0.0040159675312827) | Error
: 0.18735789804394898Based on the Bethe free energy below, John knows that the loopy belief propagation has actually converged after 20 iterations:
# drop first iteration, which is influenced by the `initmessages`
plot(2:20, results.free_energy[2:end], title="Free energy", xlabel="Iteration", ylabel="Free energy [nats]", legend=false)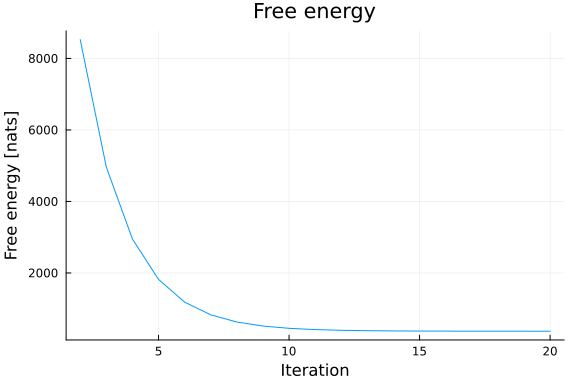
Univariate regression with unknown noise
Afterwards, he plans to test the car on a mountain road. However, mountain roads are typically narrow and filled with small stones, which makes it more difficult to establish a clear relationship between fuel consumption and speed, leading to an unknown level of noise in the regression model. Therefore, he design a model with unknown Inverse-Gamma distribution on the variance. $\begin{aligned} p(y_n \mid a, b, s) &= \mathcal{N}(y_n \mid ax_n + b, s)\\ p(s) &= \mathcal{IG}(s\mid\alpha, \theta)\\ p(a) &= \mathcal{N}(a \mid m_a, v_a) \\ p(b) &= \mathcal{N}(b \mid m_b, v_b) \end{aligned}$
@model function linear_regression_unknown_noise(x, y)
a ~ Normal(mean = 0.0, variance = 1.0)
b ~ Normal(mean = 0.0, variance = 100.0)
s ~ InverseGamma(1.0, 1.0)
y .~ Normal(mean = a .* x .+ b, variance = s)
endx_data_un, y_data_un = generate_data(0.5, 25.0, 400.0, 250)
scatter(x_data_un, y_data_un, title = "Dateset with unknown noise (mountain road)", legend=false)
xlabel!("Speed")
ylabel!("Fuel consumption")
To solve this problem in closed-from we need to resort to a variational approximation. The procedure will be a combination of variational inference and loopy belief propagation. He chooses constraints = MeanField() as a global variational approximation and provides initial marginals with the initialization argument. He is, again, going to evaluate the convergency performance of the algorithm with the free_energy = true option:
init_unknown_noise = @initialization begin
μ(b) = NormalMeanVariance(0.0, 100.0)
q(s) = vague(InverseGamma)
end
results_unknown_noise = infer(
model = linear_regression_unknown_noise(),
data = (y = y_data_un, x = x_data_un),
initialization = init_unknown_noise,
returnvars = (a = KeepLast(), b = KeepLast(), s = KeepLast()),
iterations = 20,
constraints = MeanField(),
free_energy = true
)Inference results:
Posteriors | available for (a, b, s)
Free Energy: | Real[1657.49, 1192.08, 1142.31, 1135.43, 1129.19, 1125
.47, 1123.34, 1122.13, 1121.44, 1121.05, 1120.82, 1120.69, 1120.61, 1120.56
, 1120.53, 1120.52, 1120.5, 1120.5, 1120.49, 1120.49]Based on the Bethe free energy below, John knows that his algorithm has converged after 20 iterations:
plot(results_unknown_noise.free_energy, title="Free energy", xlabel="Iteration", ylabel="Free energy [nats]", legend=false)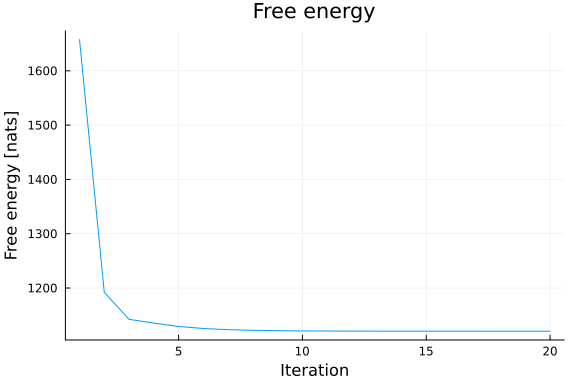
Below he visualizes the obtained posterior distributions for parameters:
pra = plot(range(-3, 3, length = 1000), (x) -> pdf(NormalMeanVariance(0.0, 1.0), x), title=L"Prior for $a$ parameter", fillalpha=0.3, fillrange = 0, label=L"$p(a)$", c=1,)
pra = vline!(pra, [ 0.5 ], label=L"True $a$", c = 3)
psa = plot(range(0.45, 0.55, length = 1000), (x) -> pdf(results_unknown_noise.posteriors[:a], x), title=L"Posterior for $a$ parameter", fillalpha=0.3, fillrange = 0, label=L"$q(a)$", c=2,)
psa = vline!(psa, [ 0.5 ], label=L"True $a$", c = 3)
plot(pra, psa, size = (1000, 200), xlabel=L"$a$", ylabel=L"$p(a)$", ylims=[0, Inf])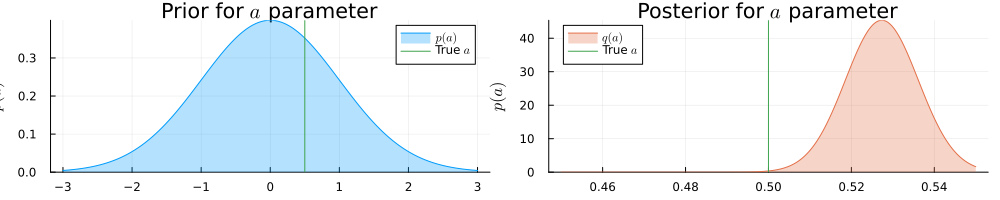
prb = plot(range(-40, 40, length = 1000), (x) -> pdf(NormalMeanVariance(0.0, 100.0), x), title=L"Prior for $b$ parameter", fillalpha=0.3, fillrange = 0, label=L"$p(b)$", c=1, legend = :topleft)
prb = vline!(prb, [ 25.0 ], label=L"True $b$", c = 3)
psb = plot(range(23, 28, length = 1000), (x) -> pdf(results_unknown_noise.posteriors[:b], x), title=L"Posterior for $b$ parameter", fillalpha=0.3, fillrange = 0, label=L"$q(b)$", c=2, legend = :topleft)
psb = vline!(psb, [ 25.0 ], label=L"True $b$", c = 3)
plot(prb, psb, size = (1000, 200), xlabel=L"$b$", ylabel=L"$p(b)$", ylims=[0, Inf])
prb = plot(range(0.001, 400, length = 1000), (x) -> pdf(InverseGamma(1.0, 1.0), x), title=L"Prior for $s$ parameter", fillalpha=0.3, fillrange = 0, label=L"$p(s)$", c=1, legend = :topleft)
prb = vline!(prb, [ 200 ], label=L"True $s$", c = 3)
psb = plot(range(0.001, 400, length = 1000), (x) -> pdf(results_unknown_noise.posteriors[:s], x), title=L"Posterior for $s$ parameter", fillalpha=0.3, fillrange = 0, label=L"$q(s)$", c=2, legend = :topleft)
psb = vline!(psb, [ 200 ], label=L"True $s$", c = 3)
plot(prb, psb, size = (1000, 200), xlabel=L"$s$", ylabel=L"$p(s)$", ylims=[0, Inf])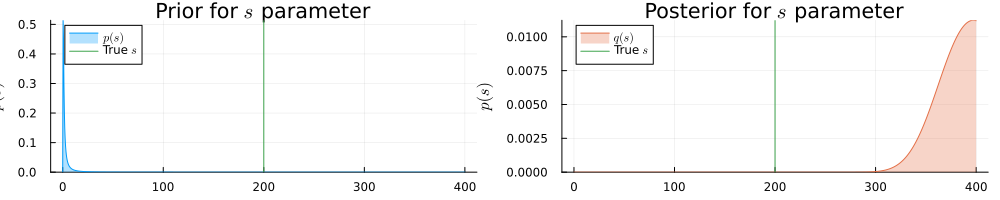
He sees that in the presence of more noise the inference result is more uncertain about the actual values for $a$ and $b$ parameters.
John samples $a$ and $b$ and plot many possible regression lines on the same plot:
as = rand(results_unknown_noise.posteriors[:a], 100)
bs = rand(results_unknown_noise.posteriors[:b], 100)
p = scatter(x_data_un, y_data_un, title = "Linear regression with more noise", legend=false)
xlabel!("Speed")
ylabel!("Fuel consumption")
for (a, b) in zip(as, bs)
global p = plot!(p, x_data_un, a .* x_data_un .+ b, alpha = 0.05, color = :red)
end
plot(p, size = (900, 400))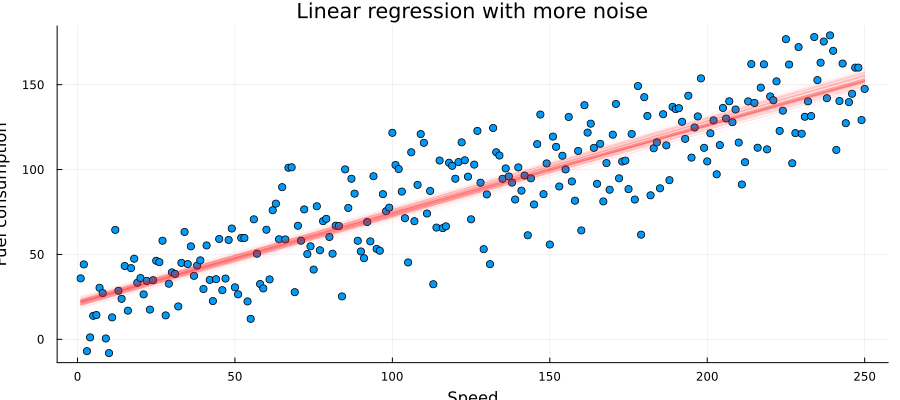
From this plot John can see that many lines do fit the data well and there is no definite "best" answer to the regression coefficients. He realize that most of these lines, however, resemble a similar angle and shift.
Multivariate linear regression
In addition to fuel consumption, he is also interested in evaluating the car's power performance, braking performance, handling stability, smoothness, and other factors. To investigate the car's performance, he includes additional measurements. Essentially, this approach involves performing multiple linear regression tasks simultaneously, using multiple data vectors for x and y with different levels of noise. As in the previous example, he assumes the level of noise to be unknown.
@model function linear_regression_multivariate(dim, x, y)
a ~ MvNormal(mean = zeros(dim), covariance = 100 * diageye(dim))
b ~ MvNormal(mean = ones(dim), covariance = 100 * diageye(dim))
W ~ InverseWishart(dim + 2, 100 * diageye(dim))
y .~ MvNormal(mean = x .* a .+ b, covariance = W)
endAfter received all the measurement records, he plots the measurements and performance index:
dim_mv = 6
nr_samples_mv = 50
rng_mv = StableRNG(42)
a_mv = randn(rng_mv, dim_mv)
b_mv = 10 * randn(rng_mv, dim_mv)
v_mv = 100 * rand(rng_mv, dim_mv)
x_data_mv, y_data_mv = collect(zip(generate_data.(a_mv, b_mv, v_mv, nr_samples_mv)...));p = plot(title = "Multivariate linear regression", legend = :topleft)
plt = palette(:tab10)
data_set_label = [""]
for k in 1:dim_mv
global p = scatter!(p, x_data_mv[k], y_data_mv[k], label = "Measurement #$k", ms = 2, color = plt[k])
end
xlabel!(L"$x$")
ylabel!(L"$y$")
p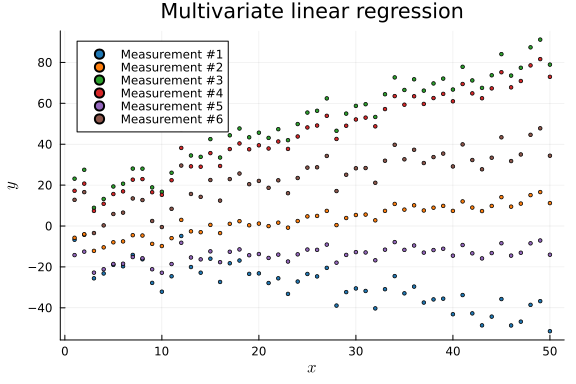
Before this data can be used to perform inference, John needs to change its format slightly.
x_data_mv_processed = map(i -> Diagonal([getindex.(x_data_mv, i)...]), 1:nr_samples_mv)
y_data_mv_processed = map(i -> [getindex.(y_data_mv, i)...], 1:nr_samples_mv);init = @initialization begin
q(W) = InverseWishart(dim_mv + 2, 10 * diageye(dim_mv))
μ(b) = MvNormalMeanCovariance(ones(dim_mv), 10 * diageye(dim_mv))
endInitial state:
q(W) = InverseWishart{Float64, PDMats.PDMat{Float64, Matrix{Float64}}}(
df: 8.0
Ψ: [10.0 0.0 … 0.0 0.0; 0.0 10.0 … 0.0 0.0; … ; 0.0 0.0 … 10.0 0.0; 0.0 0.0
… 0.0 10.0]
)
μ(b) = MvNormalMeanCovariance(
μ: [1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
Σ: [10.0 0.0 … 0.0 0.0; 0.0 10.0 … 0.0 0.0; … ; 0.0 0.0 … 10.0 0.0; 0.0 0.0
… 0.0 10.0]
)results_mv = infer(
model = linear_regression_multivariate(dim = dim_mv),
data = (y = y_data_mv_processed, x = x_data_mv_processed),
initialization = init,
returnvars = (a = KeepLast(), b = KeepLast(), W = KeepLast()),
free_energy = true,
iterations = 50,
constraints = MeanField()
)Inference results:
Posteriors | available for (a, b, W)
Free Energy: | Real[864.485, 789.026, 769.094, 750.865, 737.67, 724.7
22, 712.341, 700.865, 690.782, 682.505 … 664.434, 664.434, 664.434, 664.4
34, 664.434, 664.434, 664.434, 664.434, 664.434, 664.434]Again, the algorithm nicely converged, because the Bethe free energy reached a plateau. John also draws the results for the linear regression parameters and sees that the lines very nicely follow the provided data.
p = plot(title = "Multivariate linear regression", legend = :topleft, xlabel=L"$x$", ylabel=L"$y$")
# how many lines to plot
r = 50
i_a = collect.(eachcol(rand(results_mv.posteriors[:a], r)))
i_b = collect.(eachcol(rand(results_mv.posteriors[:b], r)))
plt = palette(:tab10)
for k in 1:dim_mv
x_mv_k = x_data_mv[k]
y_mv_k = y_data_mv[k]
for i in 1:r
global p = plot!(p, x_mv_k, x_mv_k .* i_a[i][k] .+ i_b[i][k], label = nothing, alpha = 0.05, color = plt[k])
end
global p = scatter!(p, x_mv_k, y_mv_k, label = "Measurement #$k", ms = 2, color = plt[k])
end
# truncate the init step
f = plot(results_mv.free_energy[2:end], title ="Bethe free energy convergence", label = nothing, xlabel = "Iteration", ylabel = "Bethe free energy [nats]")
plot(p, f, size = (1000, 400))
He needs more iterations to converge in comparison to the very first example, but that is expected since the problem became multivariate and, hence, more difficult.
i_a_mv = results_mv.posteriors[:a]
ps_a = []
for k in 1:dim_mv
local _p = plot(title = L"Estimated $a_{%$k}$", xlabel=L"$a_{%$k}$", ylabel=L"$p(a_{%$k})$", xlims = (-1.5,1.5), xticks=[-1.5, 0, 1.5], ylims=[0, Inf])
local m_a_mv_k = mean(i_a_mv)[k]
local v_a_mv_k = std(i_a_mv)[k, k]
_p = plot!(_p, Normal(m_a_mv_k, v_a_mv_k), fillalpha=0.3, fillrange = 0, label=L"$q(a_{%$k})$", c=2,)
_p = vline!(_p, [ a_mv[k] ], label=L"True $a_{%$k}$", c = 3)
push!(ps_a, _p)
end
plot(ps_a...)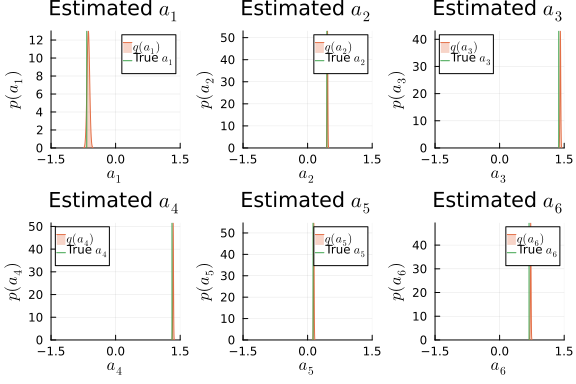
i_b_mv = results_mv.posteriors[:b]
ps_b = []
for k in 1:dim_mv
local _p = plot(title = L"Estimated $b_{%$k}$", xlabel=L"$b_{%$k}$", ylabel=L"$p(b_{%$k})$", xlims = (-20,20), xticks=[-20, 0, 20], ylims =[0, Inf])
local m_b_mv_k = mean(i_b_mv)[k]
local v_b_mv_k = std(i_b_mv)[k, k]
_p = plot!(_p, Normal(m_b_mv_k, v_b_mv_k), fillalpha=0.3, fillrange = 0, label=L"$q(b_{%$k})$", c=2,)
_p = vline!(_p, [ b_mv[k] ], label=L"Real $b_{%$k}$", c = 3)
push!(ps_b, _p)
end
plot(ps_b...)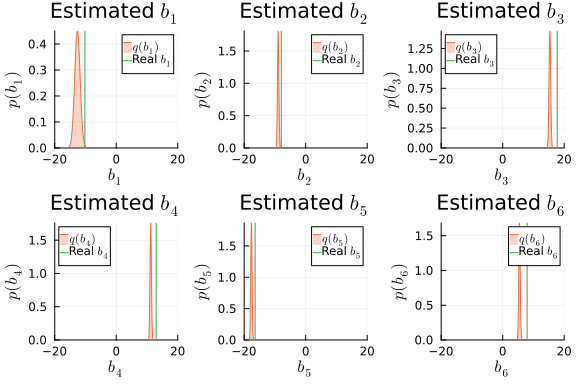
He also checks the noise estimation procedure and sees that the noise variance are currently a bit underestimated. Note here that he neglects the covariance terms between the individual elements, which might result in this kind of behaviour.
scatter(1:dim_mv, v_mv, ylims=(0, 100), label=L"True $s_d$")
scatter!(1:dim_mv, diag(mean(results_mv.posteriors[:W])); yerror=sqrt.(diag(var(results_mv.posteriors[:W]))), label=L"$\mathrm{E}[s_d] \pm \sigma$")
plot!(; xlabel=L"Dimension $d$", ylabel="Variance", title="Estimated variance of the noise")
Part 2. Hierarchical Bayesian Linear Regression
Disclaimer The tutorial below is an adaptation of the Bayesian Hierarchical Linear Regression tutorial implemented in NumPyro.
The original author in NumPyro is Carlos Souza. Updated by Chris Stoafer in NumPyro. Adapted to RxInfer by Dmitry Bagaev.
Probabilistic Machine Learning models can not only make predictions about future data but also model uncertainty. In areas such as personalized medicine, there might be a large amount of data, but there is still a relatively small amount available for each patient. To customize predictions for each person, it becomes necessary to build a model for each individual — considering its inherent uncertainties — and then couple these models together in a hierarchy so that information can be borrowed from other similar individuals [1].
The purpose of this tutorial is to demonstrate how to implement a Bayesian Hierarchical Linear Regression model using RxInfer. To provide motivation for the tutorial, I will use the OSIC Pulmonary Fibrosis Progression competition, hosted on Kaggle.
# https://www.machinelearningplus.com/linear-regression-in-julia/
# https://nbviewer.org/github/pyro-ppl/numpyro/blob/master/notebooks/source/bayesian_hierarchical_linear_regression.ipynbUnderstanding the Task
Pulmonary fibrosis is a disorder characterized by scarring of the lungs, and its cause and cure are currently unknown. In this competition, the objective was to predict the severity of decline in lung function for patients. Lung function is assessed based on the output from a spirometer, which measures the forced vital capacity (FVC), representing the volume of air exhaled.
In medical applications, it is valuable to evaluate a model's confidence in its decisions. As a result, the metric used to rank the teams was designed to reflect both the accuracy and certainty of each prediction. This metric is a modified version of the Laplace Log Likelihood (further details will be provided later).
Now, let's explore the data and dig deeper into the problem involved.
dataset = CSV.read("../data/hbr/osic_pulmonary_fibrosis.csv", DataFrame);describe(dataset)7×7 DataFrame
Row │ variable mean min median max
⋯
│ Symbol Union… Any Union… Any
⋯
─────┼─────────────────────────────────────────────────────────────────────
─────
1 │ Patient ID00007637202177411956430 ID004266
372 ⋯
2 │ Weeks 31.8618 -5 28.0 133
3 │ FVC 2690.48 827 2641.0 6399
4 │ Percent 77.6727 28.8776 75.6769 153.145
5 │ Age 67.1885 49 68.0 88
⋯
6 │ Sex Female Male
7 │ SmokingStatus Currently smokes Never sm
oke
3 columns om
ittedfirst(dataset, 5)5×7 DataFrame
Row │ Patient Weeks FVC Percent Age Sex Sm
oki ⋯
│ String31 Int64 Int64 Float64 Int64 String7 St
rin ⋯
─────┼─────────────────────────────────────────────────────────────────────
─────
1 │ ID00007637202177411956430 -4 2315 58.2536 79 Male Ex
-sm ⋯
2 │ ID00007637202177411956430 5 2214 55.7121 79 Male Ex
-sm
3 │ ID00007637202177411956430 7 2061 51.8621 79 Male Ex
-sm
4 │ ID00007637202177411956430 9 2144 53.9507 79 Male Ex
-sm
5 │ ID00007637202177411956430 11 2069 52.0634 79 Male Ex
-sm ⋯
1 column om
ittedThe dataset provided us with a baseline chest CT scan and relevant clinical information for a group of patients. Each patient has an image taken at Week = 0, and they undergo numerous follow-up visits over approximately 1-2 years, during which their Forced Vital Capacity (FVC) is measured. For the purpose of this tutorial, we will only consider the Patient ID, the weeks, and the FVC measurements, discarding all other information. Restricting our analysis to these specific columns allowed our team to achieve a competitive score, highlighting the effectiveness of Bayesian hierarchical linear regression models, especially when dealing with uncertainty, which is a crucial aspect of the problem.
Since this is real medical data, the relative timing of FVC measurements varies widely, as shown in the 3 sample patients below:
patientinfo(dataset, patient_id) = filter(:Patient => ==(patient_id), dataset)patientinfo (generic function with 1 method)function patientchart(dataset, patient_id; line_kws = true)
info = patientinfo(dataset, patient_id)
x = info[!, "Weeks"]
y = info[!, "FVC"]
p = plot(tickfontsize = 10, margin = 1Plots.cm, size = (400, 400), titlefontsize = 11)
p = scatter!(p, x, y, title = patient_id, legend = false, xlabel = "Weeks", ylabel = "FVC")
if line_kws
# Use the `GLM.jl` package to estimate linear regression
linearFormulae = @formula(FVC ~ Weeks)
linearRegressor = lm(linearFormulae, patientinfo(dataset, patient_id))
linearPredicted = predict(linearRegressor)
p = plot!(p, x, linearPredicted, color = :red, lw = 3)
end
return p
endpatientchart (generic function with 1 method)p1 = patientchart(dataset, "ID00007637202177411956430")
p2 = patientchart(dataset, "ID00009637202177434476278")
p3 = patientchart(dataset, "ID00010637202177584971671")
plot(p1, p2, p3, layout = @layout([ a b c ]), size = (1200, 400))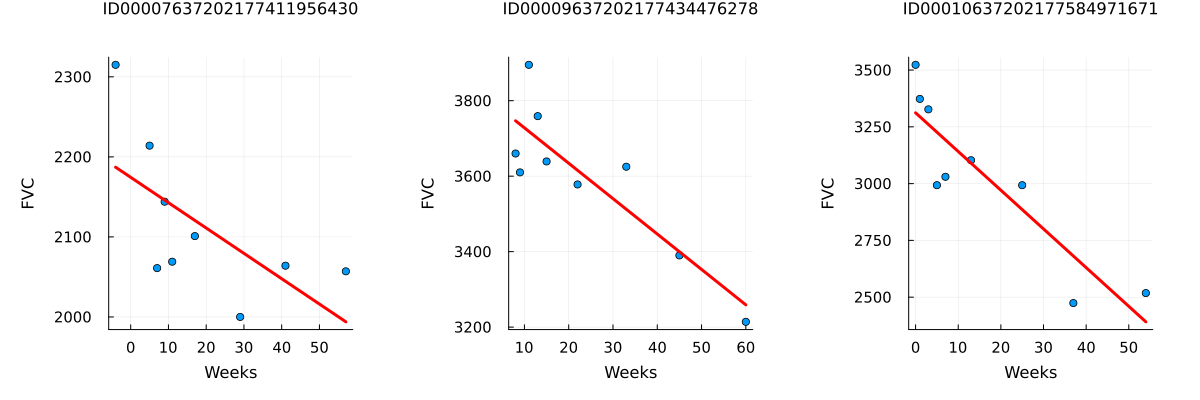
On average, each of the 176 patients provided in the dataset had 9 visits during which their FVC was measured. These visits occurred at specific weeks within the interval [-12, 133]. The decline in lung capacity is evident, but it also varies significantly from one patient to another.
Our task was to predict the FVC measurements for each patient at every possible week within the [-12, 133] interval, along with providing a confidence score for each prediction. In other words, we were required to fill a matrix, as shown below, with the predicted values and their corresponding confidence scores:

The task was ideal for applying Bayesian inference. However, the vast majority of solutions shared within the Kaggle community utilized discriminative machine learning models, disregarding the fact that most discriminative methods struggle to provide realistic uncertainty estimates. This limitation stems from their typical training process, which aims to optimize parameters to minimize certain loss criteria (such as predictive error). As a result, these models do not inherently incorporate uncertainty into their parameters or subsequent predictions. While some methods may produce uncertainty estimates as a by-product or through post-processing steps, these are often heuristic-based and lack a statistically principled approach to estimate the target uncertainty distribution [2].
Modelling: Bayesian Hierarchical Linear Regression with Partial Pooling
In a basic linear regression, which is not hierarchical, the assumption is that all FVC decline curves share the same α and β values. This model is known as the "pooled model." On the other extreme, we could assume a model where each patient has a personalized FVC decline curve, and these curves are entirely independent of one another. This model is referred to as the "unpooled model," where each patient has completely separate regression lines.
In this analysis, we will adopt a middle ground approach known as "Partial pooling." Specifically, we will assume that while α's and β's are different for each patient, as in the unpooled case, these coefficients share some similarities. This partial pooling will be achieved by modeling each individual coefficient as being drawn from a common group distribution.:
Mathematically, the model is described by the following equations:
\[\begin{equation} \begin{aligned} \mu_\alpha &\sim \mathcal{N}(\mathrm{mean} = 0.0, \mathrm{variance} = 250000.0) \\ \sigma_\alpha &\sim \mathcal{\Gamma}(\mathrm{shape} = 1.75, \mathrm{scale} = 45.54) \\ \mu_\beta &\sim \mathcal{N}(\mathrm{mean} = 0.0, \mathrm{variance} = 9.0) \\ \sigma_\beta &\sim \mathcal{\Gamma}(\mathrm{shape} = 1.75, \mathrm{scale} = 1.36) \\ \alpha_i &\sim \mathcal{N}(\mathrm{mean} = \mu_\alpha, \mathrm{precision} = \sigma_\alpha) \\ \beta &\sim \mathcal{N}(\mathrm{mean} = \mu_\beta, \mathrm{precision} = \sigma_\beta) \\ \sigma &\sim \mathcal{\Gamma}(\mathrm{shape} = 1.75, \mathrm{scale} = 45.54) \\ \mathrm{FVC}_{ij} &\sim \mathcal{N}(\mathrm{mean} = \alpha_i + t \beta_i, \mathrm{precision} = \sigma) \end{aligned} \end{equation}\]
where t is the time in weeks. Those are very uninformative priors, but that's ok: our model will converge!
Implementing this model in RxInfer is pretty straightforward:
@model function partially_pooled(patient_codes, weeks, data)
μ_α ~ Normal(mean = 0.0, var = 250000.0) # Prior for the mean of α (intercept)
μ_β ~ Normal(mean = 0.0, var = 9.0) # Prior for the mean of β (slope)
σ_α ~ Gamma(shape = 1.75, scale = 45.54) # Prior for the precision of α (intercept)
σ_β ~ Gamma(shape = 1.75, scale = 1.36) # Prior for the precision of β (slope)
n_codes = length(patient_codes) # Total number of data points
n_patients = length(unique(patient_codes)) # Number of unique patients in the data
local α # Individual intercepts for each patient
local β # Individual slopes for each patient
for i in 1:n_patients
α[i] ~ Normal(mean = μ_α, precision = σ_α) # Sample the intercept α from a Normal distribution
β[i] ~ Normal(mean = μ_β, precision = σ_β) # Sample the slope β from a Normal distribution
end
σ ~ Gamma(shape = 1.75, scale = 45.54) # Prior for the standard deviation of the error term
local FVC_est
for i in 1:n_codes
FVC_est[i] ~ α[patient_codes[i]] + β[patient_codes[i]] * weeks[i] # FVC estimation using patient-specific α and β
data[i] ~ Normal(mean = FVC_est[i], precision = σ) # Likelihood of the observed FVC data
end
endVariational constraints are used in variational methods to restrict the set of functions or probability distributions that the method can explore during optimization. These constraints help guide the optimization process towards more meaningful and tractable solutions. We need variational constraints to ensure that the optimization converges to valid and interpretable solutions, avoiding solutions that might not be meaningful or appropriate for the given problem. By incorporating constraints, we can control the complexity and shape of the solutions, making them more useful for practical applications. We use the @constraints macro from RxInfer to define approriate variational constraints.
@constraints function partially_pooled_constraints()
# Assume that `μ_α`, `σ_α`, `μ_β`, `σ_β` and `σ` are jointly independent
q(μ_α, σ_α, μ_β, σ_β, σ) = q(μ_α)q(σ_α)q(μ_β)q(σ_β)q(σ)
# Assume that `μ_α`, `σ_α`, `α` are jointly independent
q(μ_α, σ_α, α) = q(μ_α, α)q(σ_α)
# Assume that `μ_β`, `σ_β`, `β` are jointly independent
q(μ_β, σ_β, β) = q(μ_β, β)q(σ_β)
# Assume that `FVC_est`, `σ` are jointly independent
q(FVC_est, σ) = q(FVC_est)q(σ)
endpartially_pooled_constraints (generic function with 1 method)These @constraints assume some structural independencies in the resulting variational approximation. For simplicity we can also use constraints = MeanField() in the inference function below. That's all for modelling!
Inference in the model
A significant achievement of Probabilistic Programming Languages, like RxInfer, is the ability to separate model specification and inference. Once I define my generative model with priors, condition statements, and data likelihoods, I can delegate the challenging inference tasks to RxInfer's inference engine.
Calling the inference engine only takes a few lines of code. Before proceeding, let's assign a numerical Patient ID to each patient code, a task that can be easily accomplished using label encoding.
patient_ids = dataset[!, "Patient"] # get the column of all patients
patient_code_encoder = Dict(map(((id, patient), ) -> patient => id, enumerate(unique(patient_ids))));
patient_code_column = map(patient -> patient_code_encoder[patient], patient_ids)
dataset[!, :PatientCode] = patient_code_column
first(patient_code_encoder, 5)5-element Vector{Pair{InlineStrings.String31, Int64}}:
"ID00197637202246865691526" => 85
"ID00388637202301028491611" => 160
"ID00341637202287410878488" => 142
"ID00020637202178344345685" => 9
"ID00305637202281772703145" => 127function partially_pooled_inference(dataset)
patient_codes = values(dataset[!, "PatientCode"])
weeks = values(dataset[!, "Weeks"])
FVC_obs = values(dataset[!, "FVC"]);
init = @initialization begin
μ(α) = vague(NormalMeanVariance)
μ(β) = vague(NormalMeanVariance)
q(α) = vague(NormalMeanVariance)
q(β) = vague(NormalMeanVariance)
q(σ) = vague(Gamma)
q(σ_α) = vague(Gamma)
q(σ_β) = vague(Gamma)
end
results = infer(
model = partially_pooled(patient_codes = patient_codes, weeks = weeks),
data = (data = FVC_obs, ),
options = (limit_stack_depth = 500, ),
constraints = partially_pooled_constraints(),
initialization = init,
returnvars = KeepLast(),
iterations = 100
)
endpartially_pooled_inference (generic function with 1 method)We use a hybrid message passing approach combining exact and variational inference. In loopy models, where there are cycles or feedback loops in the graphical model, we need to initialize messages to kick-start the message passing process. Messages are passed between connected nodes in the model to exchange information and update beliefs iteratively. Initializing messages provides a starting point for the iterative process and ensures that the model converges to a meaningful solution.
In variational inference procedures, we need to initialize marginals because variational methods aim to approximate the true posterior distribution with a simpler, tractable distribution. Initializing marginals involves providing initial estimates for the parameters of this approximating distribution. These initial estimates serve as a starting point for the optimization process, allowing the algorithm to iteratively refine the approximation until it converges to a close approximation of the true posterior distribution.
partially_pooled_inference_results = partially_pooled_inference(dataset)Inference results:
Posteriors | available for (α, σ_α, σ_β, σ, FVC_est, μ_β, μ_α, β)Checking the model
Inspecting the learned parameters
# Convert to `Normal` since it supports easy plotting with `StatsPlots`
let
local μ_α = Normal(mean_std(partially_pooled_inference_results.posteriors[:μ_α])...)
local μ_β = Normal(mean_std(partially_pooled_inference_results.posteriors[:μ_β])...)
local α = map(d -> Normal(mean_std(d)...), partially_pooled_inference_results.posteriors[:α])
local β = map(d -> Normal(mean_std(d)...), partially_pooled_inference_results.posteriors[:β])
local p1 = plot(μ_α, title = "q(μ_α)", fill = 0, fillalpha = 0.2, label = false)
local p2 = plot(μ_β, title = "q(μ_β)", fill = 0, fillalpha = 0.2, label = false)
local p3 = plot(title = "q(α)...", legend = false)
local p4 = plot(title = "q(β)...", legend = false)
foreach(d -> plot!(p3, d), α) # Add each individual `α` on plot `p3`
foreach(d -> plot!(p4, d), β) # Add each individual `β` on plot `p4`
plot(p1, p2, p3, p4, size = (1200, 400), layout = @layout([ a b; c d ]))
end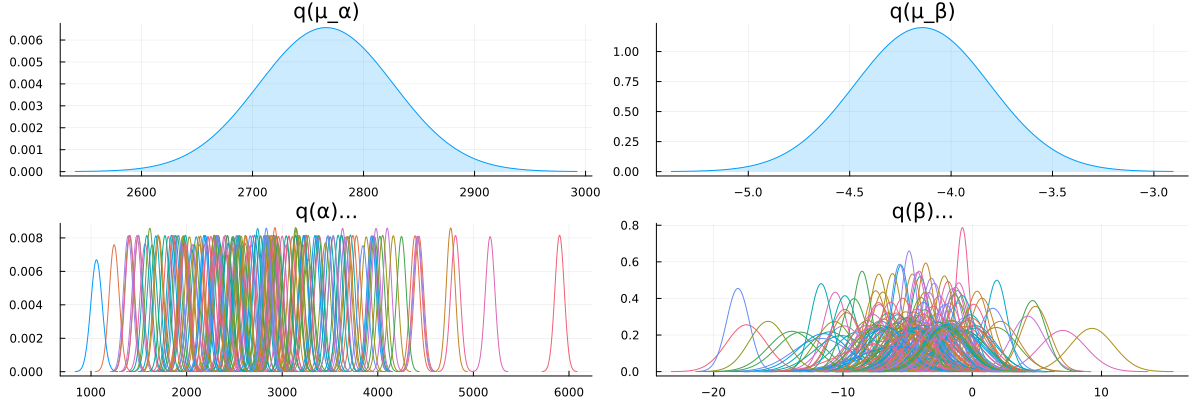
Looks like our model learned personalized alphas and betas for each patient!
Visualizing FVC decline curves for some patients
Now, let's visually inspect the FVC decline curves predicted by our model. We will complete the FVC table by predicting all the missing values. To do this, we need to create a table to accommodate the predictions.
function patientchart_bayesian(results, dataset, encoder, patient_id; kwargs...)
info = patientinfo(dataset, patient_id)
patient_code_id = encoder[patient_id]
patient_α = results.posteriors[:α][patient_code_id]
patient_β = results.posteriors[:β][patient_code_id]
estimated_σ = inv(mean(results.posteriors[:σ]))
predict_weeks = range(-12, 134)
predicted = map(predict_weeks) do week
pm = mean(patient_α) + mean(patient_β) * week
pv = var(patient_α) + var(patient_β) * week ^ 2 + estimated_σ
return pm, sqrt(pv)
end
p = patientchart(dataset, patient_id; kwargs...)
return plot!(p, predict_weeks, getindex.(predicted, 1), ribbon = getindex.(predicted, 2), color = :orange)
endpatientchart_bayesian (generic function with 1 method)p1 = patientchart_bayesian(partially_pooled_inference_results, dataset, patient_code_encoder, "ID00007637202177411956430")
p2 = patientchart_bayesian(partially_pooled_inference_results, dataset, patient_code_encoder, "ID00009637202177434476278")
p3 = patientchart_bayesian(partially_pooled_inference_results, dataset, patient_code_encoder, "ID00011637202177653955184")
plot(p1, p2, p3, layout = @layout([ a b c ]), size = (1200, 400))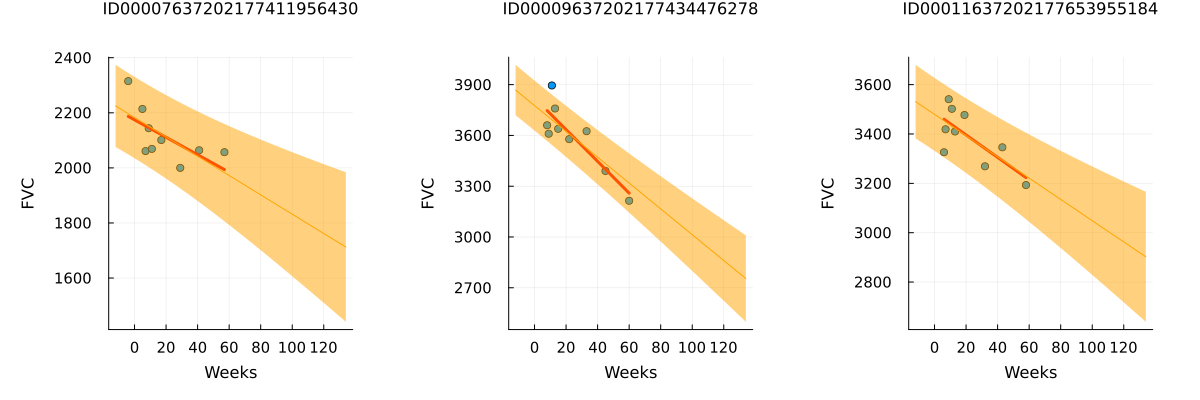
The results match our expectations perfectly! Let's highlight the observations:
The model successfully learned Bayesian Linear Regressions! The orange line representing the learned predicted FVC mean closely aligns with the red line representing the deterministic linear regression. More importantly, the model effectively predicts uncertainty, demonstrated by the light orange region surrounding the mean FVC line.
The model predicts higher uncertainty in cases where the data points are more dispersed, such as in the 1st and 3rd patients. In contrast, when data points are closely grouped together, as seen in the 2nd patient, the model predicts higher confidence, resulting in a narrower light orange region.
Additionally, across all patients, we observe that the uncertainty increases as we look further into the future. The light orange region widens as the number of weeks increases, reflecting the growth of uncertainty over time.
Computing the modified Laplace Log Likelihood and RMSE
As mentioned earlier, the competition evaluated models using a modified version of the Laplace Log Likelihood, which takes into account both the accuracy and certainty of each prediction—a valuable feature in medical applications.
To compute the metric, we predicted both the FVC value and its associated confidence measure (standard deviation σ). The metric is given by the formula:
\[\begin{equation} \begin{aligned} \sigma_{\mathrm{clipped}} &= \max(\sigma, 70) \\ \delta &= \min(\vert \mathrm{FVC}_{\mathrm{true}} - \mathrm{FVC}_{\mathrm{pred}}\vert, 1000) \\ \mathrm{metric} &= -\frac{\sqrt{2}\delta}{\sigma_{\mathrm{clipped}}} - \mathrm{ln}(\sqrt{2}\sigma_{\mathrm{clipped}}) \\ \end{aligned} \end{equation}\]
To prevent large errors from disproportionately penalizing results, errors were thresholded at 1000 ml. Additionally, confidence values were clipped at 70 ml to account for the approximate measurement uncertainty in FVC. The final score was determined by averaging the metric across all (Patient, Week) pairs. It is worth noting that metric values will be negative, and a higher score indicates better model performance.
function FVC_predict(results)
return broadcast(results.posteriors[:FVC_est], Ref(results.posteriors[:σ])) do f, s
return @call_rule NormalMeanPrecision(:out, Marginalisation) (m_μ = f, q_τ = s)
end
endFVC_predict (generic function with 1 method)function compute_rmse(results, dataset)
FVC_predicted = FVC_predict(results)
return mean((dataset[!, "FVC"] .- mean.(FVC_predicted)) .^ 2) ^ (1/2)
end
function compute_laplace_log_likelihood(results, dataset)
FVC_predicted = FVC_predict(results)
sigma_c = std.(FVC_predicted)
sigma_c[sigma_c .< 70] .= 70
delta = abs.(mean.(FVC_predicted) .- dataset[!, "FVC"])
delta[delta .> 1000] .= 1000
return mean(-sqrt(2) .* delta ./ sigma_c .- log.(sqrt(2) .* sigma_c))
endcompute_laplace_log_likelihood (generic function with 1 method)println("RMSE: $(compute_rmse(partially_pooled_inference_results, dataset))")
println("Laplace Log Likelihood: $(compute_laplace_log_likelihood(partially_pooled_inference_results, dataset))")RMSE: 124.01306457993996
Laplace Log Likelihood: -6.156795767593613What do these numbers signify? They indicate that adopting this approach would lead to outperforming the majority of public solutions in the competition. In several seconds of inference!
Interestingly, most public solutions rely on a standard deterministic Neural Network and attempt to model uncertainty through a quantile loss, adhering to a frequentist approach. The importance of uncertainty in single predictions is growing in the field of machine learning, becoming a crucial requirement. Especially when the consequences of an inaccurate prediction are significant, knowing the probability distribution of individual predictions becomes essential.
Add layer to model hierarchy: Smoking Status
We can enhance the model by incorporating the column "SmokingStatus" as a pooling level, where model parameters will be partially pooled within the groups "Never smoked," "Ex-smoker," and "Currently smokes." To achieve this, we need to:
Encode the "SmokingStatus" column. Map the patient encoding to the corresponding "SmokingStatus" encodings. Refine and retrain the model with the additional hierarchical structure.
combine(groupby(dataset, "SmokingStatus"), nrow)3×2 DataFrame
Row │ SmokingStatus nrow
│ String31 Int64
─────┼─────────────────────────
1 │ Ex-smoker 1038
2 │ Never smoked 429
3 │ Currently smokes 82smoking_id_mapping = Dict(map(((code, smoking_status), ) -> smoking_status => code, enumerate(unique(dataset[!, "SmokingStatus"]))))
smoking_code_encoder = Dict(map(unique(values(patient_ids))) do patient_id
smoking_status = first(unique(patientinfo(dataset, patient_id)[!, "SmokingStatus"]))
return patient_code_encoder[patient_id] => smoking_id_mapping[smoking_status]
end)
smoking_status_patient_mapping = map(id -> smoking_code_encoder[id], 1:length(unique(patient_ids)));@model function partially_pooled_with_smoking(patient_codes, smoking_status_patient_mapping, weeks, data)
μ_α_global ~ Normal(mean = 0.0, var = 250000.0) # Prior for the mean of α (intercept)
μ_β_global ~ Normal(mean = 0.0, var = 250000.0) # Prior for the mean of β (slope)
σ_α_global ~ Gamma(shape = 1.75, scale = 45.54) # Corresponds to half-normal with scale 100.0
σ_β_global ~ Gamma(shape = 1.75, scale = 1.36) # Corresponds to half-normal with scale 3.0
n_codes = length(patient_codes) # Total number of data points
n_smoking_statuses = length(unique(smoking_status_patient_mapping)) # Number of different smoking patterns
n_patients = length(unique(patient_codes)) # Number of unique patients in the data
local μ_α_smoking_status # Individual intercepts for smoking pattern
local μ_β_smoking_status # Individual slopes for smoking pattern
for i in 1:n_smoking_statuses
μ_α_smoking_status[i] ~ Normal(mean = μ_α_global, precision = σ_α_global)
μ_β_smoking_status[i] ~ Normal(mean = μ_β_global, precision = σ_β_global)
end
local α # Individual intercepts for each patient
local β # Individual slopes for each patient
for i in 1:n_patients
α[i] ~ Normal(mean = μ_α_smoking_status[smoking_status_patient_mapping[i]], precision = σ_α_global)
β[i] ~ Normal(mean = μ_β_smoking_status[smoking_status_patient_mapping[i]], precision = σ_β_global)
end
σ ~ Gamma(shape = 1.75, scale = 45.54) # Corresponds to half-normal with scale 100.0
local FVC_est
for i in 1:n_codes
FVC_est[i] ~ α[patient_codes[i]] + β[patient_codes[i]] * weeks[i] # FVC estimation using patient-specific α and β
data[i] ~ Normal(mean = FVC_est[i], precision = σ) # Likelihood of the observed FVC data
end
end
@constraints function partially_pooled_with_smooking_constraints()
q(μ_α_global, σ_α_global, μ_β_global, σ_β_global) = q(μ_α_global)q(σ_α_global)q(μ_β_global)q(σ_β_global)
q(μ_α_smoking_status, μ_β_smoking_status, σ_α_global, σ_β_global) = q(μ_α_smoking_status)q(μ_β_smoking_status)q(σ_α_global)q(σ_β_global)
q(μ_α_global, σ_α_global, μ_β_global, σ_β_global, σ) = q(μ_α_global)q(σ_α_global)q(μ_β_global)q(σ_β_global)q(σ)
q(μ_α_global, σ_α_global, α) = q(μ_α_global, α)q(σ_α_global)
q(μ_β_global, σ_β_global, β) = q(μ_β_global, β)q(σ_β_global)
q(FVC_est, σ) = q(FVC_est)q(σ)
endpartially_pooled_with_smooking_constraints (generic function with 1 method)function partially_pooled_with_smoking(dataset, smoking_status_patient_mapping)
patient_codes = values(dataset[!, "PatientCode"])
weeks = values(dataset[!, "Weeks"])
FVC_obs = values(dataset[!, "FVC"]);
init = @initialization begin
μ(α) = vague(NormalMeanVariance)
μ(β) = vague(NormalMeanVariance)
q(σ) = Gamma(1.75, 45.54)
q(σ_α_global) = Gamma(1.75, 45.54)
q(σ_β_global) = Gamma(1.75, 1.36)
end
return infer(
model = partially_pooled_with_smoking(
patient_codes = patient_codes,
smoking_status_patient_mapping = smoking_status_patient_mapping,
weeks = weeks
),
data = (data = FVC_obs, ),
options = (limit_stack_depth = 500, ),
constraints = partially_pooled_with_smooking_constraints(),
initialization = init,
returnvars = KeepLast(),
iterations = 100,
)
endpartially_pooled_with_smoking (generic function with 3 methods)partially_pooled_with_smoking_inference_results = partially_pooled_with_smoking(dataset, smoking_status_patient_mapping);Inspect the learned parameters
# Convert to `Normal` since it supports easy plotting with `StatsPlots`
let
local μ_α = Normal(mean_std(partially_pooled_with_smoking_inference_results.posteriors[:μ_α_global])...)
local μ_β = Normal(mean_std(partially_pooled_with_smoking_inference_results.posteriors[:μ_β_global])...)
local αsmoking = map(d -> Normal(mean_std(d)...), partially_pooled_with_smoking_inference_results.posteriors[:μ_α_smoking_status])
local βsmoking = map(d -> Normal(mean_std(d)...), partially_pooled_with_smoking_inference_results.posteriors[:μ_β_smoking_status])
local α = map(d -> Normal(mean_std(d)...), partially_pooled_with_smoking_inference_results.posteriors[:α])
local β = map(d -> Normal(mean_std(d)...), partially_pooled_with_smoking_inference_results.posteriors[:β])
local p1 = plot(μ_α, title = "q(μ_α_global)", fill = 0, fillalpha = 0.2, label = false)
local p2 = plot(μ_β, title = "q(μ_β_global)", fill = 0, fillalpha = 0.2, label = false)
local p3 = plot(title = "q(α)...", legend = false)
local p4 = plot(title = "q(β)...", legend = false)
foreach(d -> plot!(p3, d), α) # Add each individual `α` on plot `p3`
foreach(d -> plot!(p4, d), β) # Add each individual `β` on plot `p4`
local p5 = plot(title = "q(μ_α_smoking_status)...", legend = false)
local p6 = plot(title = "q(μ_β_smoking_status)...", legend = false)
foreach(d -> plot!(p5, d, fill = 0, fillalpha = 0.2), αsmoking)
foreach(d -> plot!(p6, d, fill = 0, fillalpha = 0.2), βsmoking)
plot(p1, p2, p3, p4, p5, p6, size = (1200, 600), layout = @layout([ a b; c d; e f ]))
end
Interpret smoking status model parameters
The model parameters for each smoking status reveal intriguing findings, particularly concerning the trend, μ_β_smoking_status. In the summary below, it is evident that the trend for current smokers has a positive mean, while the trend for ex-smokers and those who have never smoked is negative.
smoking_id_mappingDict{InlineStrings.String31, Int64} with 3 entries:
"Currently smokes" => 3
"Ex-smoker" => 1
"Never smoked" => 2posteriors_μ_β_smoking_status = partially_pooled_with_smoking_inference_results.posteriors[:μ_β_smoking_status]
println("Trend for")
foreach(pairs(smoking_id_mapping)) do (key, id)
println(" $key: $(mean(posteriors_μ_β_smoking_status[id]))")
endTrend for
Currently smokes: 1.8147143381168995
Ex-smoker: -4.572743474510769
Never smoked: -4.447769588035918Let's look at these curves for individual patients to help interpret these model results.
# Never smoked
p1 = patientchart_bayesian(partially_pooled_with_smoking_inference_results, dataset, patient_code_encoder, "ID00007637202177411956430")
# Ex-smoker
p2 = patientchart_bayesian(partially_pooled_with_smoking_inference_results, dataset, patient_code_encoder, "ID00009637202177434476278")
# Currently smokes
p3 = patientchart_bayesian(partially_pooled_with_smoking_inference_results, dataset, patient_code_encoder, "ID00011637202177653955184")
plot(p1, p2, p3, layout = @layout([ a b c ]), size = (1200, 400))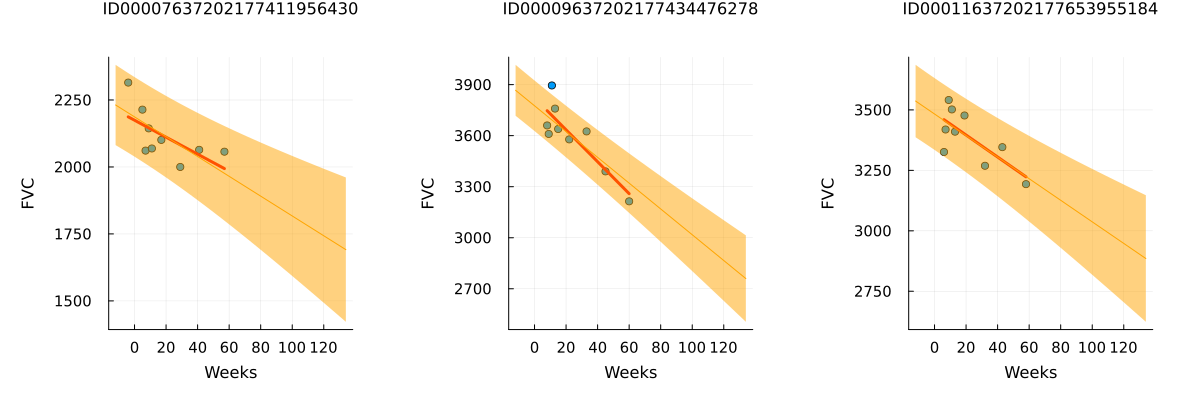
Review patients that currently smoke
When plotting each patient with the smoking status "Currently smokes," we observe different trends. Some patients show a clear positive trend, while others do not exhibit a clear trend or even have a negative trend. Compared to the unpooled trend lines, the trend lines with partial pooling are less prone to overfitting and display greater uncertainty in both slope and intercept.
Depending on the purpose of the model, we can proceed in different ways:
If our goal is to gain insights into how different attributes relate to a patient's FVC over time, we can stop here and understand that current smokers might experience an increase in FVC over time when monitored for Pulmonary Fibrosis. We may then formulate hypotheses to explore the reasons behind this observation and design new experiments for further testing.
However, if our aim is to develop a model for generating predictions to treat patients, it becomes crucial to ensure that the model does not overfit and can be trusted with new patients. To achieve this, we could adjust model parameters to shrink the "Currently smokes" group's parameters closer to the global parameters, or even consider merging the group with "Ex-smokers." Additionally, collecting more data for current smokers could help in ensuring the model's robustness and preventing overfitting.
let
local plots = []
for (i, patient) in enumerate(unique(filter(:SmokingStatus => ==("Currently smokes"), dataset)[!, "Patient"]))
push!(plots, patientchart_bayesian(partially_pooled_with_smoking_inference_results, dataset, patient_code_encoder, patient))
end
plot(plots..., size = (1200, 1200))
end
Modified Laplace Log Likelihood and RMSE for model with Smoking Status Level
We calculate the metrics for the updated model and compare to the original model.
println("RMSE: $(compute_rmse(partially_pooled_with_smoking_inference_results, dataset))")
println("Laplace Log Likelihood: $(compute_laplace_log_likelihood(partially_pooled_with_smoking_inference_results, dataset))")RMSE: 124.81042940540623
Laplace Log Likelihood: -6.165660148605184Both the Laplace Log Likelihood and RMSE indicate slightly worse performance for the smoking status model. Adding this hierarchy level as it is did not improve the model's performance significantly. However, we did discover some interesting results from the smoking status level that might warrant further investigation. Additionally, we could attempt to enhance model performance by adjusting priors or exploring different hierarchy levels, such as gender.
References
[1] Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 521, 452–459 (2015). https://doi.org/10.1038/nature14541
[2] Rainforth, Thomas William Gamlen. Automating Inference, Learning, and Design Using Probabilistic Programming. University of Oxford, 2017.