This example has been auto-generated from the examples/ folder at GitHub repository.
Invertible neural networks: a tutorial
# Activate local environment, see `Project.toml`
import Pkg; Pkg.activate(".."); Pkg.instantiate();Table of contents
Introduction
Load required packages
Before we can start, we need to import some packages:
using RxInfer
using Random
using StableRNGs
using ReactiveMP # ReactiveMP is included in RxInfer, but we explicitly use some of its functionality
using LinearAlgebra # only used for some matrix specifics
using Plots # only used for visualisation
using Distributions # only used for sampling from multivariate distributions
using Optim # only used for parameter optimisationModel specification
Specifying an invertible neural network model is easy. The general recipe looks like follows: model = FlowModel(input_dim, (layer1(options), layer2(options), ...)). Here the first argument corresponds to the input dimension of the model and the second argument is a tuple of layers. An example model can be defined as
model = FlowModel(2,
(
AdditiveCouplingLayer(PlanarFlow()),
AdditiveCouplingLayer(PlanarFlow(); permute=false)
)
);Alternatively, the input_dim can also be passed as an InputLayer layer as
model = FlowModel(
(
InputLayer(2),
AdditiveCouplingLayer(PlanarFlow()),
AdditiveCouplingLayer(PlanarFlow(); permute=false)
)
);In the above AdditiveCouplingLayer layers the input ${\bf{x}} = [x_1, x_2, \ldots, x_N]$ is partitioned into chunks of unit length. These partitions are additively coupled to an output ${\bf{y}} = [y_1, y_2, \ldots, y_N]$ as
\[\begin{aligned} y_1 &= x_1 \\ y_2 &= x_2 + f_1(x_1) \\ \vdots \\ y_N &= x_N + f_{N-1}(x_{N-1}) \end{aligned}\]
Importantly, this structure can easily be converted as
\[\begin{aligned} x_1 &= y_1 \\ x_2 &= y_2 - f_1(x_1) \\ \vdots \\ x_N &= y_N - f_{N-1}(x_{N-1}) \end{aligned}\]
\[f_n\]
is an arbitrarily complex function, here chosen to be a PlanarFlow, but this can be interchanged for any function or neural network. The permute keyword argument (which defaults to true) specifies whether the output of this layer should be randomly permuted or shuffled. This makes sure that the first element is also transformed in consecutive layers.
A permutation layer can also be added by itself as a PermutationLayer layer with a custom permutation matrix if desired.
model = FlowModel(
(
InputLayer(2),
AdditiveCouplingLayer(PlanarFlow(); permute=false),
PermutationLayer(PermutationMatrix(2)),
AdditiveCouplingLayer(PlanarFlow(); permute=false)
)
);Model compilation
In the current models, the layers are setup to work with the passed input dimension. This means that the function $f_n$ is repeated input_dim-1 times for each of the partitions. Furthermore the permutation layers are set up with proper permutation matrices. If we print the model we get
modelFlowModel{3, Tuple{ReactiveMP.AdditiveCouplingLayerEmpty{Tuple{ReactiveMP.P
lanarFlowEmpty{1}}}, PermutationLayer{Int64}, ReactiveMP.AdditiveCouplingLa
yerEmpty{Tuple{ReactiveMP.PlanarFlowEmpty{1}}}}}(2, (ReactiveMP.AdditiveCou
plingLayerEmpty{Tuple{ReactiveMP.PlanarFlowEmpty{1}}}(2, (ReactiveMP.Planar
FlowEmpty{1}(),), 1), PermutationLayer{Int64}(2, [0 1; 1 0]), ReactiveMP.Ad
ditiveCouplingLayerEmpty{Tuple{ReactiveMP.PlanarFlowEmpty{1}}}(2, (Reactive
MP.PlanarFlowEmpty{1}(),), 1)))The text below describes the terms above. Please note the distinction in typing and elements, i.e. FlowModel{types}(elements):
FlowModel- specifies that we are dealing with a flow model.3- Number of layers.Tuple{AdditiveCouplingLayerEmpty{...},PermutationLayer{Int64},AdditiveCouplingLayerEmpty{...}}- tuple of layer types.Tuple{ReactiveMP.PlanarFlowEmpty{1},ReactiveMP.PlanarFlowEmpty{1}}- tuple of functions $f_n$.PermutationLayer{Int64}(2, [0 1; 1 0])- permutation layer with input dimension 2 and permutation matrix[0 1; 1 0].
From inspection we can see that the AdditiveCouplingLayerEmpty and PlanarFlowEmpty objects are different than before. They are initialized for the correct dimension, but they do not have any parameters registered to them. This is by design to allow for separating the model specification from potential optimization procedures. Before we perform inference in this model, the parameters should be initialized. We can randomly initialize the parameters as
compiled_model = compile(model)CompiledFlowModel{3, Tuple{AdditiveCouplingLayer{Tuple{PlanarFlow{Float64,
Float64}}}, PermutationLayer{Int64}, AdditiveCouplingLayer{Tuple{PlanarFlow
{Float64, Float64}}}}}(2, (AdditiveCouplingLayer{Tuple{PlanarFlow{Float64,
Float64}}}(2, (PlanarFlow{Float64, Float64}(-1.0775858704601136, 1.68840249
2843819, 0.6506168127803081),), 1), PermutationLayer{Int64}(2, [0 1; 1 0]),
AdditiveCouplingLayer{Tuple{PlanarFlow{Float64, Float64}}}(2, (PlanarFlow{
Float64, Float64}(0.7692333817975537, -0.3166389864812192, 0.04457741824104
775),), 1)))Now we can see that random parameters have been assigned to the individual functions inside of our model. Alternatively if we would like to pass our own parameters, then this is also possible. You can easily find the required number of parameters using the nr_params(model) function.
compiled_model = compile(model, randn(StableRNG(321), nr_params(model)))CompiledFlowModel{3, Tuple{AdditiveCouplingLayer{Tuple{PlanarFlow{Float64,
Float64}}}, PermutationLayer{Int64}, AdditiveCouplingLayer{Tuple{PlanarFlow
{Float64, Float64}}}}}(2, (AdditiveCouplingLayer{Tuple{PlanarFlow{Float64,
Float64}}}(2, (PlanarFlow{Float64, Float64}(0.7296412319250487, -0.97673361
28037319, -0.4749869451771002),), 1), PermutationLayer{Int64}(2, [0 1; 1 0]
), AdditiveCouplingLayer{Tuple{PlanarFlow{Float64, Float64}}}(2, (PlanarFlo
w{Float64, Float64}(0.3490911082645933, -0.8184067956921087, -1.45782147323
52386),), 1)))Probabilistic inference
We can perform inference in our compiled model through standard usage of RxInfer and its underlying ReactiveMP inference engine. Let's first generate some random 2D data which has been sampled from a standard normal distribution and is consecutively passed through an invertible neural network. Using the forward(model, data) function we can propagate data in the forward direction.
function generate_data(nr_samples::Int64, model::CompiledFlowModel; seed = 123)
rng = StableRNG(seed)
# specify latent sampling distribution
dist = MvNormal([1.5, 0.5], I)
# sample from the latent distribution
x = rand(rng, dist, nr_samples)
# transform data
y = zeros(Float64, size(x))
for k = 1:nr_samples
y[:,k] .= ReactiveMP.forward(model, x[:,k])
end
# return data
return y, x
end;# generate data
y, x = generate_data(1000, compiled_model)
# plot generated data
p1 = scatter(x[1,:], x[2,:], alpha=0.3, title="Original data", size=(800,400))
p2 = scatter(y[1,:], y[2,:], alpha=0.3, title="Transformed data", size=(800,400))
plot(p1, p2, legend = false)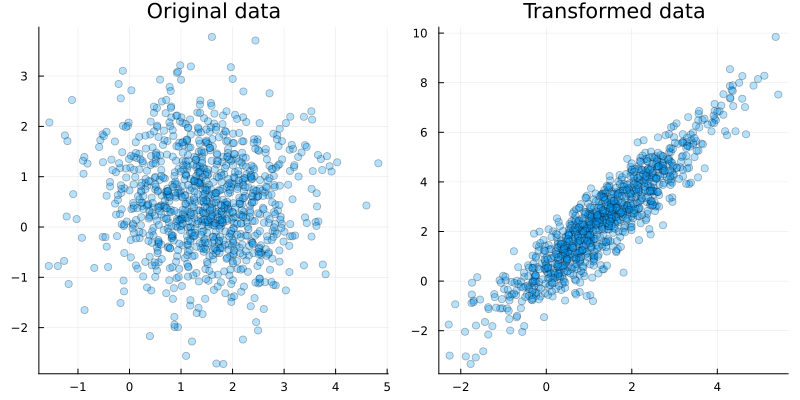
The probabilistic model for doing inference can be described as
@model function invertible_neural_network(y)
# specify prior
z_μ ~ MvNormalMeanCovariance(zeros(2), huge*diagm(ones(2)))
z_Λ ~ Wishart(2.0, tiny*diagm(ones(2)))
# specify observations
for k in eachindex(y)
# specify latent state
x[k] ~ MvNormalMeanPrecision(z_μ, z_Λ)
# specify transformed latent value
y_lat[k] ~ Flow(x[k])
# specify observations
y[k] ~ MvNormalMeanCovariance(y_lat[k], tiny*diagm(ones(2)))
end
end;Here the model is passed inside a meta data object of the flow node. Inference then resorts to
observations = [y[:,k] for k=1:size(y,2)]
fmodel = invertible_neural_network()
data = (y = observations, )
initialization = @initialization begin
q(z_μ) = MvNormalMeanCovariance(zeros(2), huge*diagm(ones(2)))
q(z_Λ) = Wishart(2.0, tiny*diagm(ones(2)))
end
returnvars = (z_μ = KeepLast(), z_Λ = KeepLast(), x = KeepLast(), y_lat = KeepLast())
constraints = @constraints begin
q(z_μ, x, z_Λ) = q(z_μ)q(z_Λ)q(x)
end
@meta function fmeta(model)
compiled_model = compile(model, randn(StableRNG(321), nr_params(model)))
Flow(y_lat, x) -> FlowMeta(compiled_model) # defaults to FlowMeta(compiled_model; approximation=Linearization()).
# other approximation methods can be e.g. FlowMeta(compiled_model; approximation=Unscented(input_dim))
end
# First execution is slow due to Julia's initial compilation
result = infer(
model = fmodel,
data = data,
constraints = constraints,
meta = fmeta(model),
initialization = initialization,
returnvars = returnvars,
free_energy = true,
iterations = 10,
showprogress = false
)Inference results:
Posteriors | available for (z_μ, z_Λ, y_lat, x)
Free Energy: | Real[29485.3, 23762.9, 23570.6, 23570.6, 23570.6, 2357
0.6, 23570.6, 23570.6, 23570.6, 23570.6]fe_flow = result.free_energy
zμ_flow = result.posteriors[:z_μ]
zΛ_flow = result.posteriors[:z_Λ]
x_flow = result.posteriors[:x]
y_flow = result.posteriors[:y_lat];As we can see, the variational free energy decreases inside of our model.
plot(1:10, fe_flow/size(y,2), xlabel="iteration", ylabel="normalized variational free energy [nats/sample]", legend=false)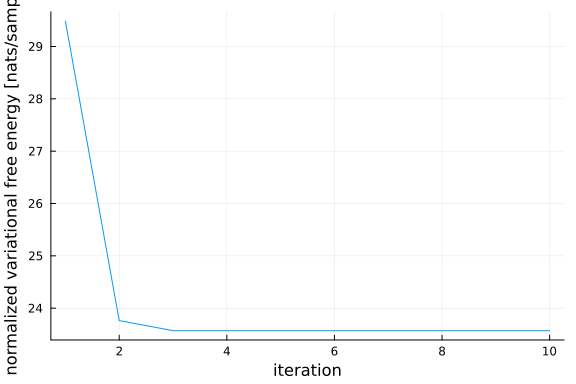
If we plot a random noisy observation and its approximated transformed uncertainty we obtain:
# pick a random observation
id = rand(StableRNG(321), 1:size(y,2))
rand_observation = MvNormal(y[:,id], 5e-1*diagm(ones(2)))
warped_observation = MvNormal(ReactiveMP.backward(compiled_model, y[:,id]), ReactiveMP.inv_jacobian(compiled_model, y[:,id])*5e-1*diagm(ones(2))*ReactiveMP.inv_jacobian(compiled_model, y[:,id])');
p1 = scatter(x[1,:], x[2,:], alpha=0.1, title="Latent distribution", size=(1200,500), label="generated data")
contour!(-5:0.1:5, -5:0.1:5, (x, y) -> pdf(MvNormal([1.5, 0.5], I), [x, y]), c=:viridis, colorbar=false, linewidth=2)
scatter!([mean(zμ_flow)[1]], [mean(zμ_flow)[2]], color="red", markershape=:x, markersize=5, label="inferred mean")
contour!(-5:0.01:5, -5:0.01:5, (x, y) -> pdf(warped_observation, [x, y]), colors="red", levels=1, linewidth=2, colorbar=false)
scatter!([mean(warped_observation)[1]], [mean(warped_observation)[2]], color="red", label="transformed noisy observation")
p2 = scatter(y[1,:], y[2,:], alpha=0.1, label="generated data")
scatter!([ReactiveMP.forward(compiled_model, mean(zμ_flow))[1]], [ReactiveMP.forward(compiled_model, mean(zμ_flow))[2]], color="red", marker=:x, label="inferred mean")
contour!(-10:0.1:10, -10:0.1:10, (x, y) -> pdf(MvNormal([1.5, 0.5], I), ReactiveMP.backward(compiled_model, [x, y])), c=:viridis, colorbar=false, linewidth=2)
contour!(-10:0.1:10, -10:0.1:10, (x, y) -> pdf(rand_observation, [x, y]), colors="red", levels=1, linewidth=2, label="random noisy observation", colorba=false)
scatter!([mean(rand_observation)[1]], [mean(rand_observation)[2]], color="red", label="random noisy observation")
plot(p1, p2, legend = true)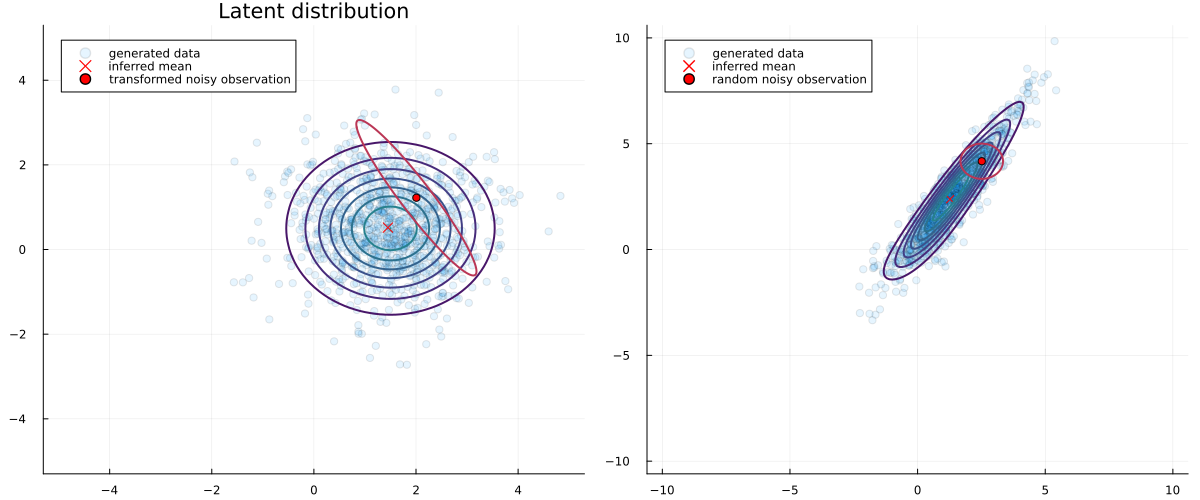
Parameter estimation
The flow model is often used to learn unknown probabilistic mappings. Here we will demonstrate it as follows for a binary classification task with the following data:
function generate_data(nr_samples::Int64; seed = 123)
rng = StableRNG(seed)
# sample weights
w = rand(rng, nr_samples, 2)
# sample appraisal
y = zeros(Float64, nr_samples)
for k = 1:nr_samples
y[k] = 1.0*(w[k,1] > 0.5)*(w[k,2] < 0.5)
end
# return data
return y, w
end;data_y, data_x = generate_data(50);
scatter(data_x[:,1], data_x[:,2], marker_z=data_y, xlabel="w1", ylabel="w2", colorbar=false, legend=false)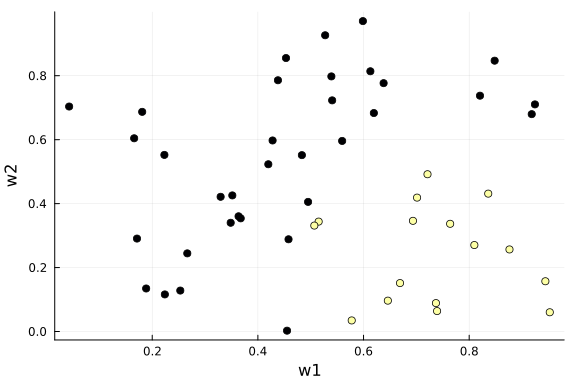
We will then specify a possible model as
# specify flow model
model = FlowModel(2,
(
AdditiveCouplingLayer(PlanarFlow()), # defaults to AdditiveCouplingLayer(PlanarFlow(); permute=true)
AdditiveCouplingLayer(PlanarFlow()),
AdditiveCouplingLayer(PlanarFlow()),
AdditiveCouplingLayer(PlanarFlow(); permute=false)
)
);The corresponding probabilistic model for the binary classification task can be created as
@model function invertible_neural_network_classifier(x, y)
# specify observations
for k in eachindex(x)
# specify latent state
x_lat[k] ~ MvNormalMeanPrecision(x[k], 1e3*diagm(ones(2)))
# specify transformed latent value
y_lat1[k] ~ Flow(x_lat[k])
y_lat2[k] ~ dot(y_lat1[k], [1, 1])
# specify observations
y[k] ~ Probit(y_lat2[k]) # default: where { pipeline = RequireMessage(in = NormalMeanPrecision(0, 1.0)) }
end
end;fcmodel = invertible_neural_network_classifier()
data = (y = data_y, x = [data_x[k,:] for k=1:size(data_x,1)], )
@meta function fmeta(model, params)
compiled_model = compile(model, params)
Flow(y_lat1, x_lat) -> FlowMeta(compiled_model)
endfmeta (generic function with 2 methods)Here we see that the compilation occurs inside of our probabilistic model. As a result we can pass parameters (and a model) to this function which we wish to opmize for some criterium, such as the variational free energy. Inference can be described as
For the optimization procedure, we will simplify our inference loop, such that it only accepts parameters as an argument (which is wishes to optimize) and outputs a performance metric.
function f(params)
Random.seed!(123) # Flow uses random permutation matrices, which is not good for the optimisation procedure
result = infer(
model = fcmodel,
data = data,
meta = fmeta(model, params),
free_energy = true,
free_energy_diagnostics = nothing, # Free Energy can be set to NaN due to optimization procedure
iterations = 10,
showprogress = false
);
result.free_energy[end]
end;Optimization can be performed using the Optim package. Alternatively, other (custom) optimizers can be implemented, such as:
res = optimize(f, randn(StableRNG(42), nr_params(model)), GradientDescent(), Optim.Options(store_trace = true, show_trace = true, show_every = 50), autodiff=:forward)- uses finitediff and is slower/less accurate.
or
# create gradient function
g = (x) -> ForwardDiff.gradient(f, x);
# specify initial params
params = randn(nr_params(model))
# create custom optimizer (here Adam)
optimizer = Adam(params; λ=1e-1)
# allocate space for gradient
∇ = zeros(nr_params(model))
# perform optimization
for it = 1:10000
# backward pass
∇ .= ForwardDiff.gradient(f, optimizer.x)
# gradient update
ReactiveMP.update!(optimizer, ∇)
end
res = optimize(f, randn(StableRNG(42), nr_params(model)), GradientDescent(), Optim.Options(f_tol = 1e-3, store_trace = true, show_trace = true, show_every = 100), autodiff=:forward)Iter Function value Gradient norm
0 5.888958e+02 8.943663e+02
* time: 0.015156984329223633
100 1.059826e+01 4.120074e+00
* time: 12.777338981628418
* Status: success
* Candidate solution
Final objective value: 1.010211e+01
* Found with
Algorithm: Gradient Descent
* Convergence measures
|x - x'| = 1.59e-03 ≰ 0.0e+00
|x - x'|/|x'| = 7.59e-04 ≰ 0.0e+00
|f(x) - f(x')| = 7.92e-03 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 7.84e-04 ≤ 1.0e-03
|g(x)| = 2.26e+00 ≰ 1.0e-08
* Work counters
Seconds run: 15 (vs limit Inf)
Iterations: 113
f(x) calls: 301
∇f(x) calls: 301optimization results are then given as
params = Optim.minimizer(res)
inferred_model = compile(model, params)
trans_data_x_1 = hcat(map((x) -> ReactiveMP.forward(inferred_model, x), [data_x[k,:] for k=1:size(data_x,1)])...)'
trans_data_x_2 = map((x) -> dot([1, 1], x), [trans_data_x_1[k,:] for k=1:size(data_x,1)])
trans_data_x_2_split = [trans_data_x_2[data_y .== 1.0], trans_data_x_2[data_y .== 0.0]]
p1 = scatter(data_x[:,1], data_x[:,2], marker_z = data_y, size=(1200,400), c=:viridis, colorbar=false, title="original data")
p2 = scatter(trans_data_x_1[:,1], trans_data_x_1[:,2], marker_z = data_y, c=:viridis, size=(1200,400), colorbar=false, title="|> warp")
p3 = histogram(trans_data_x_2_split; stacked=true, bins=50, size=(1200,400), title="|> dot")
plot(p1, p2, p3, layout=(1,3), legend=false)
using StatsFuns: normcdf
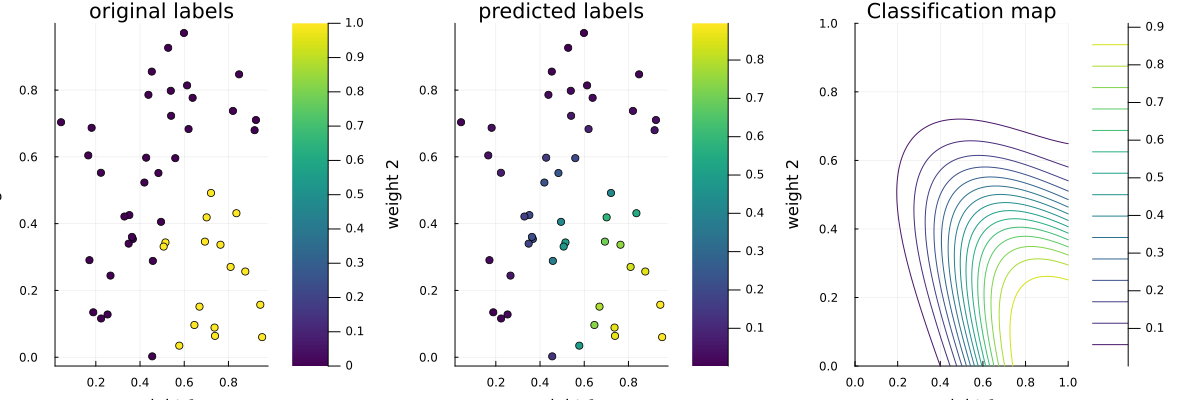
p1 = scatter(data_x[:,1], data_x[:,2], marker_z = data_y, title="original labels", xlabel="weight 1", ylabel="weight 2", size=(1200,400), c=:viridis)
p2 = scatter(data_x[:,1], data_x[:,2], marker_z = normcdf.(trans_data_x_2), title="predicted labels", xlabel="weight 1", ylabel="weight 2", size=(1200,400), c=:viridis)
p3 = contour(0:0.01:1, 0:0.01:1, (x, y) -> normcdf(dot([1,1], ReactiveMP.forward(inferred_model, [x,y]))), title="Classification map", xlabel="weight 1", ylabel="weight 2", size=(1200,400), c=:viridis)
plot(p1, p2, p3, layout=(1,3), legend=false)